I include these little projects, because the problem solving involved (identifying a need, experimenting with a solution, working within constraints) keeps instincts sharp.
Imagine you have kids and a new puppy. Our kids walk to and from school. They open the front door to get in and out of their house on the way to and from school. We had to chase our puppy, Thor, down the street a handful of times when he sneaked out between the kids legs thru the open door.


So a doggie door on the front porch.
Constraints:
- No new power tools- just my jigsaw, drill, clamps.
- Less than a hundred bucks if possible for all materials and consumables
- Will survive outdoors in Canada for more than a season,
- Looks like it fits with the wooden railings (brand consistency?)
- Reasonably robust, but relatively lightweight.
- Can be made in a few rain-free April hours.
Design:



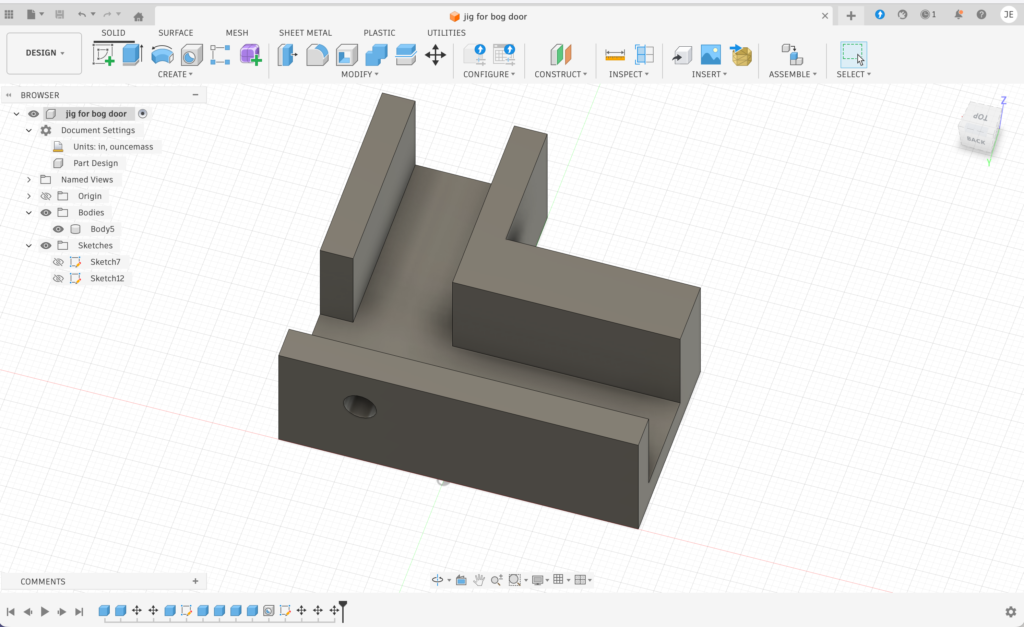
Construction is kind of a basic ladder-like shape matching the existing railing in terms of a riser spacing for 5” center to center. The door is 24” high so as to minimize waste on a 2x2x8” plank, but still match the overall railing dimensions. The frame is made from 2×2 pressure treated lumber to keep the weight down ( the railing on our porch combines 2×4 and 2×2, but the door must span 5’ and only needs to resist a 20lb dog. Weather resistant spring-return hinges and a simple catch ensure the door closes and locks when the kids forget to. To keep framing square and spacing correct,a 3-d printed jig helped to space and square the wood for fastening.
Materials and cost
- ~40 CAD for 5 planks of 2x2x8 pressure treated lumber.
- ~60 CADfor a pair of weather resistant spring return gate hinges (rated for 66 lbs, so overkill but they look real pretty)
- ~4 CAD for a painted steel catch, the kind you see on dog doors in dog parks everywhere.


Consumables:
~40 CAD for extra long (6”) jigsaw blades for cutting the lumber. I could have rented a chop saw for $40 but wanted to use what I had.
~3 CAD to 3d print a jig from PVA
With taxes this came to $160 -could probably have gotten it done for under 80 if I used $10 (30lb) painted steel spring hinges in place or the fancy ones
Now, is it puppy proof?





Good enough – First time he saw it, Thor tried to squirm thru only to get stuck between the spacers. Second time he didn’t even try, after the experience of us extracting him. It slowed him down enough so no street chasing required.